[云计算]HCIE |
您所在的位置:网站首页 › 华为fusionstorage 80技术白皮书 › [云计算]HCIE |
[云计算]HCIE
|
目录FusionStorage 简介FusionStorage 逻辑架构FusionStorage 灾备方案备份方案容灾方案FusionStorage 原理及功能特性基础概念(DHT、副本)数据路由原理FusionStorage 组件VBS 模块OSD 模块MDC 模块FusionStorage 视图FusionStorage 组件交互关系FusionStorage 副本机制FusionStorage 缓存机制写Cache流程读Cache流程FusionStorage 分布式CacheFusionStorage SSD存储与IB网络FusionStorage 掉电保护FusionStorage IO流程分析读IO流程写IO流程FusionStorage 主要功能特性总体框架SCSI/iSCSI块接口快照功能链接克隆跨资源池卷冷迁移FusionStorage 部署方式融合部署分离部署FusionStorage 组网方案网络平面
FusionStorage 简介
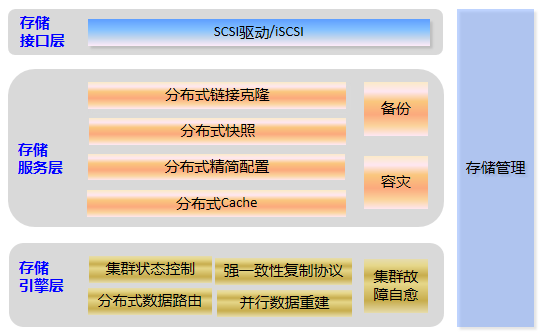
FusionStorage(华为Server SAN产品): 分布式块存储软件(主要指FusionStorage Block) 将通用x86服务器的本地HDD、SSD存储介质通过分布式技术组织成大规模存储池 对非虚拟化上层应用和虚拟机提供SCSI、iSCSI接口 开放的APIServer SAN:由多个独立服务器自带的存储组成的一个存储资源池,同时融合了计算和存储资源。 优点: 专有设备变通用设备 计算与存储线性扩展 简单管理、低TCO 与厂商专用硬件解耦 计算与存储融合TCO(Total Cost of Ownership )即总拥有成本,包括产品采购到后期使用、维护的成本。这是一种公司经常采用的技术评价标准。 FusionStorage与传统存储设备的对比的优点: 高扩展性: 传统存储设备:扩展存储需要增加控制器个数或者更换存储设备。 FusionStorage:容量与性能可线性增加,性能超越中高端存储。 高性价比: 传统存储设备:成本随性能增加,更新迭代快。 FusionStorage:支持融合部署,通用x86服务器堆叠扩展,节约成本;网络扁平化,扩容简单;已有设备利旧,保护投资。 高可靠性: 传统存储设备:硬盘故障要立刻更换,并手动恢复。 FusionStorage:提高机柜间,服务器间可靠性,故障业务无影响;硬盘故障无需手动管理,自动数据重建恢复。 并行快速数据重建: 传统存储设备:重建慢(1TB约12小时) FusionStorage:分布地数据恢复重建(1TB小于10分组)FusionStorage与传统存储设备的对比的缺点: 利用率低:FS采用两副本或三副本机制,存储利用率较低。 不支持FC网络:FS目前支持以太网、RoCE、IB网络。 部署较复杂:FS至少三节点起步,并且在节点数据达到一定规模后性能才能追上传统存储;而且在小规模的场景中实施会比传统存储复杂许多(FS需要考虑MDC、VBS、OSD及网络的规划)。 时延高:FS一般不适用于关键性的业务场景,但是可以通过IB组网、SSD Cache等方式减少时延。小规模场景:至少3台服务器,每个服务器12块硬盘(服务器级安全) 大规模场景:至少12台服务器,每个服务器12块硬盘,至少三个机柜(机柜级安全) FusionStorage两大应用场景: 虚拟化应用 高性能数据库物理部署 FusionStorage 逻辑架构
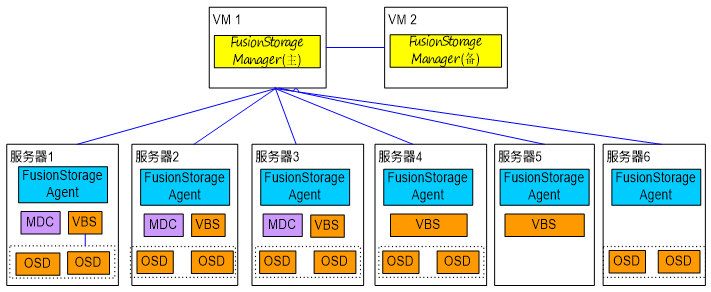
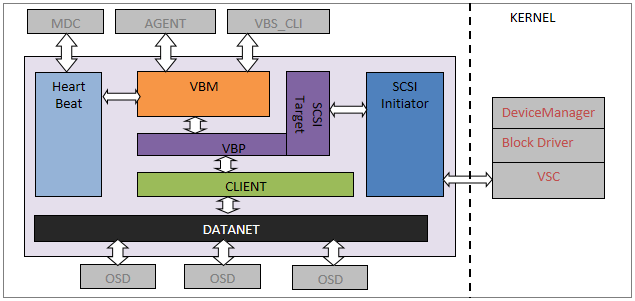
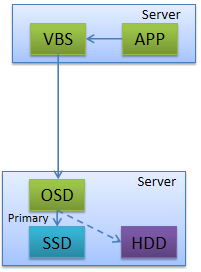
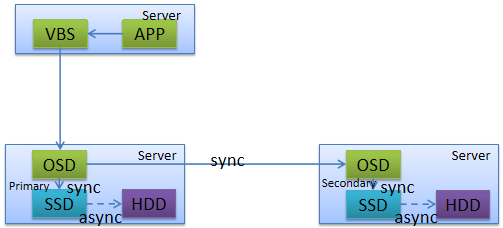
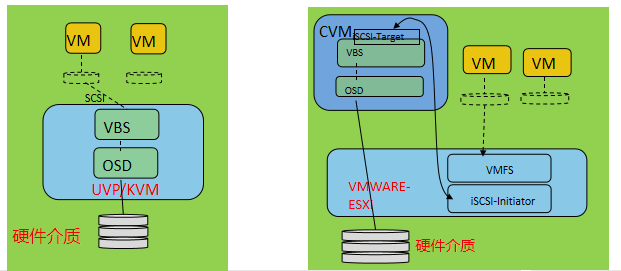
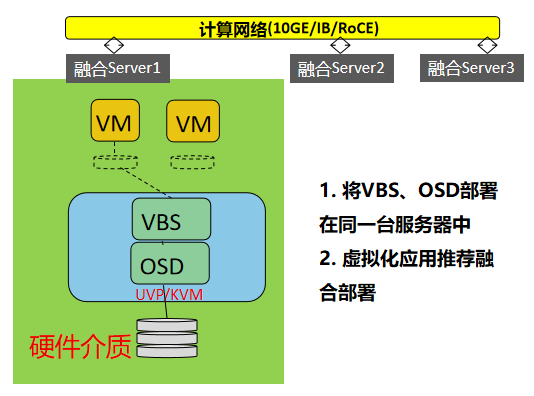
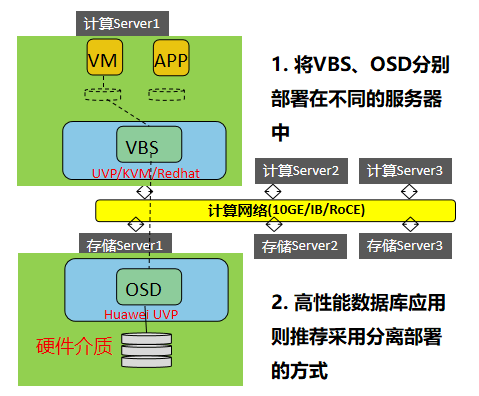
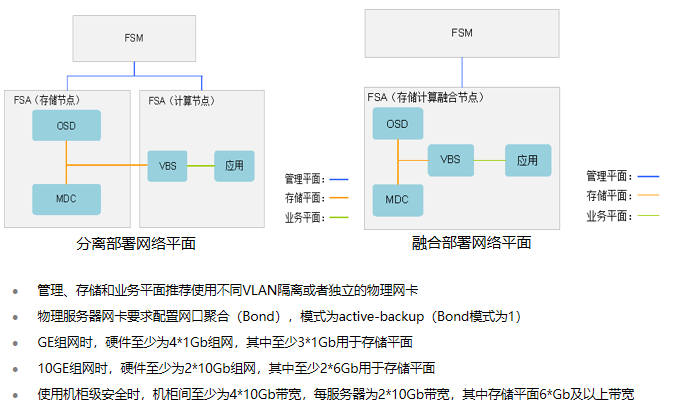
FSM(FusionStorage Manger):FusionStorage管理模块,提供告警、监控、日志、配置等操作维护功能,一般情况下FSM主备节点部署。 FSA(FusionStorage Agent):FusionStorage代理进程,实现各个节点和FSM通信。FSA包含MDC、VBS和OSD三种不同的进程,根据系统不同配置要求,分别在不同的节点上启用不同的进程组合来完成特定的功能。 MDC(MetaData Controller):元数据控制组件,实现对分布式集群的状态控制、数据重建规则等。(MDC默认部署在3个节点的ZK盘上,形成MDC集群。) VBS(Virtual Block System):虚拟块存储管理组件,负责卷元数据的管理,VBS通过SCSI或iSCSI接口提供分布式存储接入点服务,使计算资源能够通过VBS访问分布式存储资源。VBS与其所能访问的资源池的所有OSD点对点通信,使VBS能并发访问这些资源池的所有硬盘。(每个节点上默认部署一个VBS进程,形成VBS集群,节点上可通过部署多个VBS来提升IO性能。) OSD(Object Storage Device):对象存储设备服务,执行具体的I/O操作。(在每个服务器上部署多个OSD进程,一块磁盘默认对应部署一个OSD进程。在SSD卡作为主存的时候,可以部署多个OSD进程进行管理,充分发挥SSD卡的性能。) 部署方式: 融合部署: 指将VBS和OSD部署在同一台服务器中 虚拟化应用推荐采用融合部署的方式部署 分离部署: 指的是将VBS和OSD分别部署在不同的服务器中 高性能数据库应用则推荐采用分离部署的方式 FusionStorage 灾备方案 备份方案 云资源池下:全量快照、增量快照 数据库场景:NBU等通用备份软件 容灾方案 云资源池下:华为配套的容灾软件UltraVR 数据库场景:DataGuard/GoldenGate等容灾软件 FusionStorage 原理及功能特性 基础概念(DHT、副本)
DHT: Distributed Hash Table,FusionStorage中指数据路由算法 Partition:代表了一块数据分区,DHT环上的固定Hash段代表的数据区 Key-Value:底层磁盘上的数据组织成Key-Value的形式,每个Value代表一个块存储空间 Volume:应用卷,代表了应用看到的一个LBA连续编址 副本是由OSD产生的,OSD之间的关系互为主备。
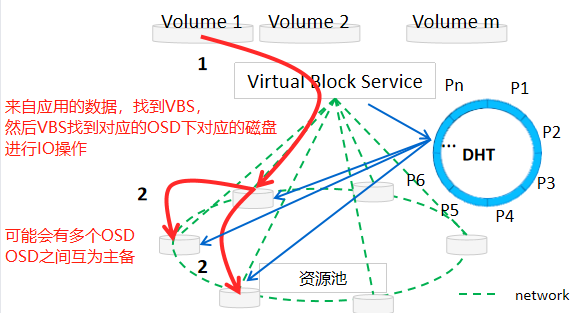
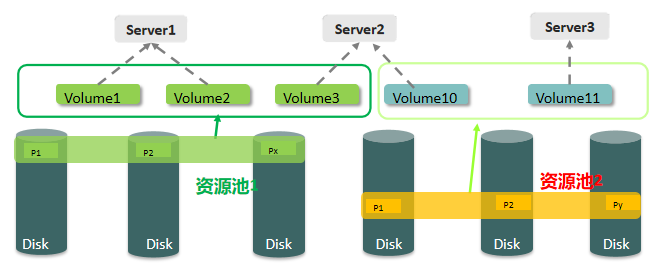
资源池:FusionStorage中一组分区构成的存储池,对应到DHT环。 Volume:应用卷,代表了应用看到的一个LBA连续编址。 系统自动将每个卷的数据块打散存储在不同服务器的不同硬盘上,冷热不均的数据会均匀分布在不同的服务器上,不会出现集中的热点。
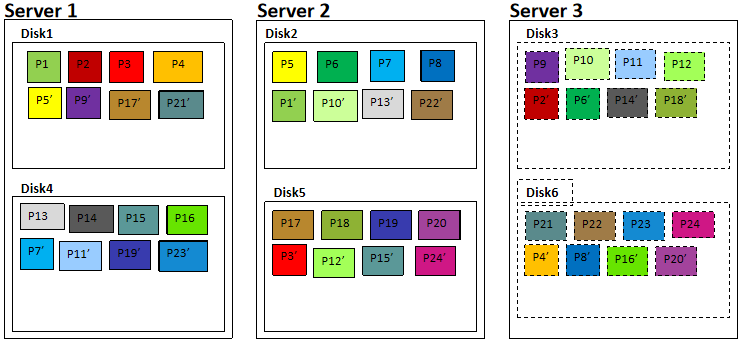
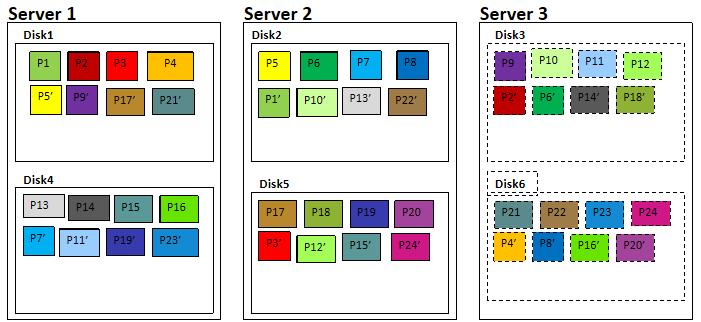
数据副本:FusionStorage采用数据多副本备份机制来保证数据的可靠性,即同一份数据可以复制保存为2~3个副本。 FusionStorage针对系统中的每一个卷,默认按照1MB进行分片,分片后的数据按照DHT算法保存到存储集群的节点上。 对于上图Server1的磁盘Disk1上的数据块P1,它的数据备份为服务器Server2的磁盘Disk2上的P1',P1和P1'构成了同一个数据块的两个副本。(当P1所在的硬盘故障时,P1'可以继续提供存储服务) 数据分片分配算法保证了主备副本在不同服务器和不同硬盘上的均匀分布。 扩容节点或者故障减容节点时,数据恢复重建算法保证了重建后系统中各节点负载的均衡性。 数据路由原理
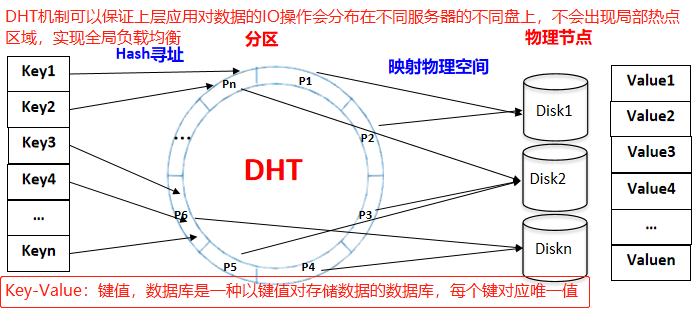
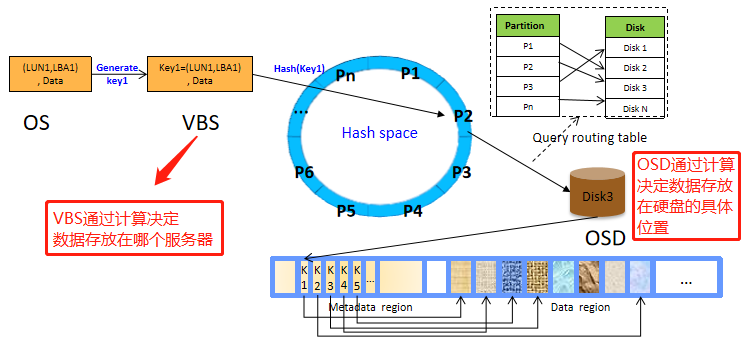
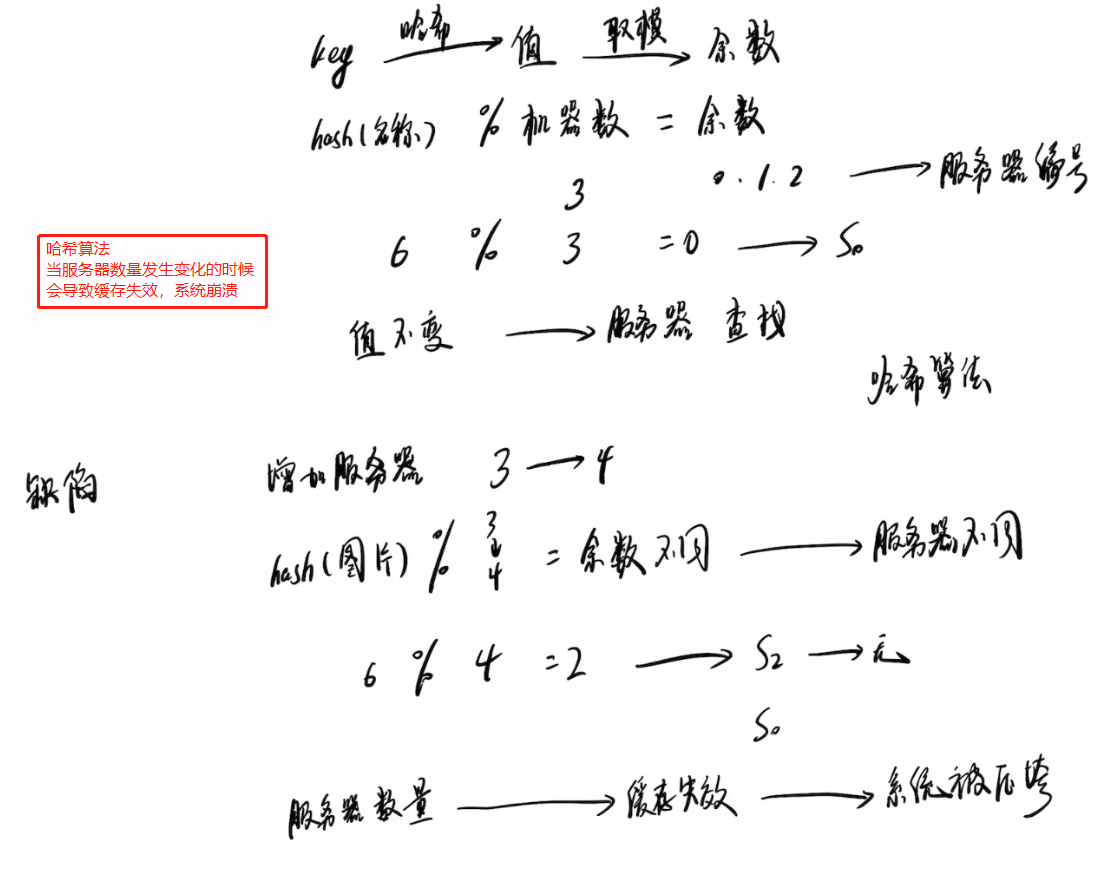
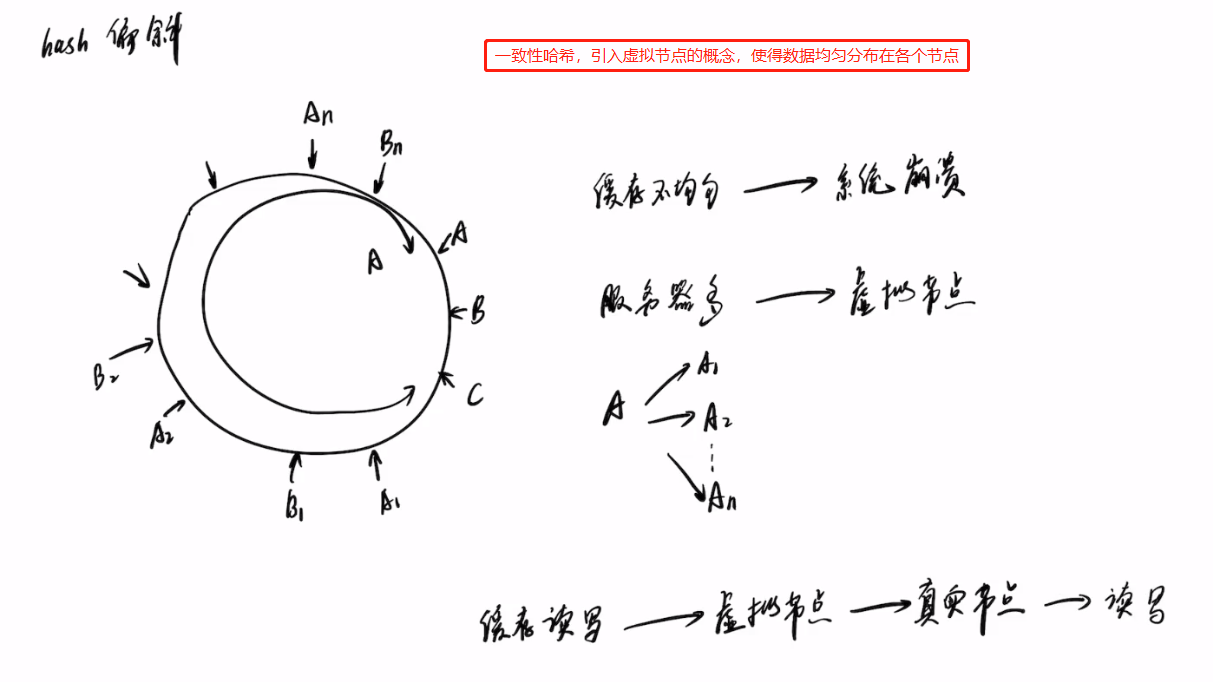
一个分布式哈希表(DHT)对应一个存储池(至少12块硬盘) VBS写到主OSD,再主OSD同步到备OSD,最后写到硬盘 FusionStorage数据路由采取分层处理方式: VBS通过计算确定数据存放在哪个服务器的哪块硬盘上。 OSD通过计算确定数据存放在硬盘的具体位置。数据路由的具体细节: 系统初始化时,FusionStorage将哈希空间(0~2^32)划分为N等份,每1等份是1个分区(Partition),这N等份按照硬盘数量进行均分。例如:在二副本场景下,系统N默认为3600(三副本场景为51200),假设当前系统有36块硬盘,则每块硬盘承载100个分区。上述“分区-硬盘”的映射关系在系统初始化的时候会分配好,后续会随着系统中硬盘数量的变化进行调整。该映射表所需要的空间很小,FusionStorage系统中的节点会在内存中保存该映射关系,用于进行快速路由。 FusionStorage会对每个LUN在逻辑上按照1MB大小进行切片,例如1GB的LUN则会被切成1024*1MB分片。当应用侧访问FusionStorage时,在SCSI命令中会带上LUN ID和LBA ID以及读写的数据内容,OS转发该消息到本节点的VBS模块,VBS根据LUN ID和LBA ID组成一个key,该key会包含LBA ID对1MB的取整计算信息。通过DHT Hash计算出一个整数(范围在0~2^32内),并落在指定的Partition中;根据内存中记录的“分区-硬盘”映射关系确定具体硬盘,VBS将IO操作转发到该硬盘所属的OSD模块。 每个OSD(或者多个)会管理一个硬盘,系统初始化时,OSD会按照1MB为单位对硬盘进行分片管理,并在硬盘的元数据管理区域记录每个1MB分片的分配信息。OSD接收到VBS发送的IO操作后,根据key查找该数据在硬盘上的具体分片信息,获取数据后返回给VBS。从而完成整个数据路由的过程。 举例:如上图,应用需要访问LUN1+LBA1地址起始的4KB长度的数据,首先构造key=LUN1+LBA1/1MB,对该key进行hash计算得到哈希值,并对N取模,得到Partition号,根据内存中记录的“分区-硬盘”映射表可得知数据归属的硬盘。(构造key→对key进行hash→取模得分区号→寻找归属硬盘进行IO操作) 一致性Hash相关资料: 聊聊一致性哈希 - 知乎 (zhihu.com) 好刚: 7分钟视频详解一致性hash 算法_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili LBA:Logic Block Address,用于寻址的逻辑块地址 2^32(Bit) = 4294967296÷1024÷1024÷1024 = 4 294 967 296(Bit) = 4(GB)
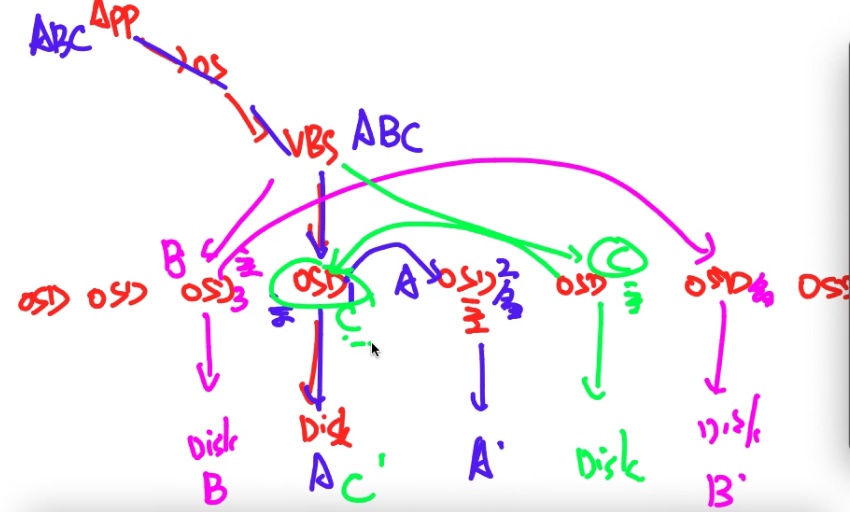
VBS在存储接入侧,负责: 卷和快照的管理功能 IO的接入和处理IO在VBS进程中需要经过三个模块的处理,分别为SCSI、VBP、CLIENT: SCSI模块负责从内核(VSC.KO)中将IO引入VBS进程,SCSI模块接收到的IO是标准SCSI协议格式的IO请求,通过SCSI四元组(host_id/channel_id/target_id/lun_id)和该IO在块设备上的offset,读写的数据长度len唯一标识一个IO,SCSI模块将收到的IO信息交给VBP(Virtual Block Process)模块。 VBP内部将通过块格式的IO转换为FusionStorage内部Key-Value格式的IO下发给CLIENT,其中KEY的组成为:tree_id(4Byte)+block_no(4Byte)+branch_i(4Byte)+snap_id(2Byte),tree_id/branch_id/snap_id是FusionStorage内部对卷、快照的唯一标识;block_no是将卷按照1M的块划分,本次IO落在哪一个1M块上的编号。 IO请求到达CLIENT模块后,Client根据KEY中的tree_id/branch_id进行hash计算,确定本次IO发给哪一个OSD进程处理确定后将IO发给对应的OSD处理。 OSD收取响应,然后逐层返回IO卷和快照的通用属性信息(如卷大小、卷名等)及卷和快照在DSware系统内部的一些私有属性(如用于定位卷和快照数据在系统中存储位置的tree_id/branch_id/snap_id)保存在DSware内部的一个私有逻辑卷中,该卷我们成为元数据卷。 VBP即将对应的SCSI数据信息转化为FusionStorage能够识别的描述信息。 OSD 模块
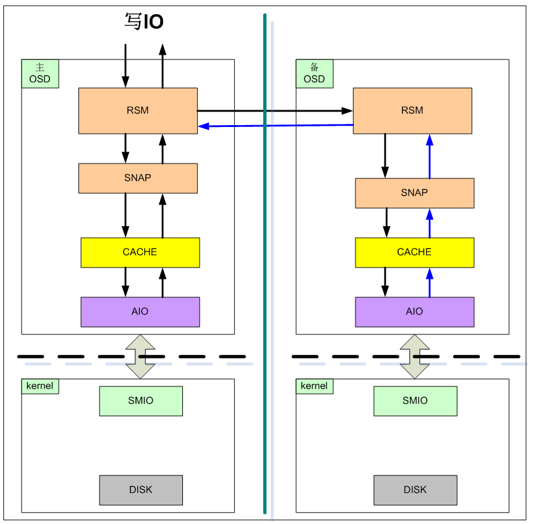
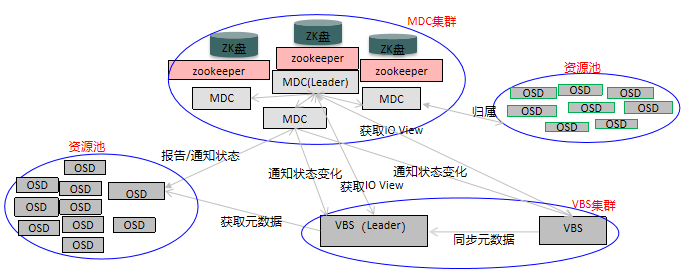
一个物理磁盘对应一个OSD进程,负责: 磁盘的管理 IO的复制 IO数据的Cache处理OSD组件功能: OSD:主备模式,MDC实施监控OSD的状态,当指定Partition所在的主OSD故障时,存储服务会实时自动切换到备OSD,保证了业务的连续性。 RSM:复制协议实现。 SNAP:实现卷与快照的IO功能、磁盘空间的管理。 CACHE:实现cache功能。 AIO:实现异步IO下发到底层SMIO模块和通过调用SMIO接口来监控介质故障。 SMIO:下发到IO到实际的物理介质、监控物理介质故障、获取磁盘信息。每个OSD会管理一个硬盘,在系统初始化时,OSD会按照1MB为单位对硬盘进行分片管理。并在硬盘的元数据管理区域记录每个1MB分片的分配信息。OSD接收到VBS发送的IO操作后,根据key查找该数据在硬盘上的具体分片信息,获取数据后返回给VBS。从而完成整个数据路由的过程。对于写请求,OSD根据分区-主磁盘-备磁盘1-备磁盘2映射表,通知各备OSD进行写操作,主与备OSD都完成写后返回VBS。 MDC 模块MDC(Metadata Controller)是一个高可靠集群,通过HA(High Availability)机制保证整个系统的高可用性和高可靠性: 通过ZooKeeper集群,实现元数据(如Topology、OSD View、Partition View、VBS View等)的可靠保存。 通过Partition分配算法,实现数据多份副本的RAID可靠性。 通过与OSD、VBS间的消息交互,实现对OSD、VBS节点的状态变化的获取与通知。 通过与Agent间的消息交互,实现系统的扩减容、状态查询、维护等。 通过心跳检测机制,实现对OSD、VBS的状态监控。Zookeeper(ZK)分布式服务框架主要用来解决分布式应用中经常遇到的,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等,ZK主要工作包括三项: MDC主备管理: MDC采用一主两备部署模式;在MDC模块进程启动后,各个MDC进程会向ZK注册选主,先注册的为主MDC;运行过程中,ZK记录MDC主备信息,并通过心跳机制监控MDC主备健康状况,一旦主MDC进程故障,会触发MDC重新选主。 数据存储:在MDC运行过程中,会生成各种控制视图信息,包括目标视图、中间视图、IO视图信息等,这些信息的保存、更新、查询、删除操作都通过ZK提供的接口实现。 数据同步:数据更新到主ZK,由主ZK自动同步到两个备ZK,保证主备ZK数据实时同步。一旦ZK发生主备切换,业务不受影响。在FusionStorage中,为保证系统可靠性,ZK采用一主两倍部署模式,每个管理节点部署一个ZK进程,ZK主备管理由ZK内部机制保证 MDC进程与ZK进程采用C/S模式,TCP协议通信;MDC可以连接到任意一个ZK服务器,并且维持TCP连接。如果这个TCP连接中断,MDC能够顺利切换到另一个ZK服务器。(ZK是MDC的服务端) FusionStorage 视图
Disk向OSD提供块服务、OSD向VBS提供对象存储服务、VBS向OS提供块服务 FusionStorage底层靠对象存储实现,对外提供块存储服务 系统启动时,MDC与ZK互动决定主MDC。主MDC与其它MDC相互监控心跳,主MDC决定某MDC故障后接替者。其它MDC发现主MDC故障又与ZK互动升任主MDC OSD启动时向MDC查询归属MDC,向归属MDC报告状态,归属MDC把状态变化发送给VBS。当归属MDC故障,主MDC指定一个MDC接管,最多两个池归属同一个MDC VBS启动时查询主MDC,向主MDC注册(主MDC维护了一个活动VBS的列表,主MDC同步VBS列表到其它MDC,以便MDC能将OSD的状态变化通知到VBS),向MDC确认自己是否为leader;VBS从主MDC获取IO View,主VBS向OSD获取元数据,其它VBS向主VBS获取元数据 FusionStorage系统中会存在多个VBS进程,如果多个VBS同时操作元数据卷,会引起数据数被写坏等问题。为避免该问题,FusionStorage系统对VBS引入了主备机制,只有主VBS可操作元数据卷,所有的备VBS不允许操作元数据卷,一套FusionStorage系统中只存在一个主VBS;VBS的主备角色由MDC进程确定,所有VBS通过和MDC间的心跳机制保证系统中不会出现双主的情况。 只有主VBS能够操作元数据,所以备VBS收到的卷和快照管理类命令需要转发到主VBS处理,对于挂载、卸载等流程,主VBS完成元数据的操作后,还需要将命令转到目标VBS实现卷的挂载、卸载等操作。 FusionStorage 副本机制
数据副本: FusionStorage采用数据多副本备份机制来保证数据的可靠性,即同一份数据可以复制保存为2~3个副本。 FusionStorage针对系统中的每1个卷,默认按照1MB进行分片,分片后的数据按照DHT算法保存集群节点上。 对于服务器Server1的 磁盘Disk1上的数据块P1,它的数据备份为服务器Server2的磁盘Disk2上P1’,P1和P1’构成了同一个数据块的两个副本。例如,当P1所在的硬盘故障时,P1’可以继续提供存储服务。 数据分片分配算法保证了主用副本和备用副本在不同服务器和不同硬盘上的均匀分布,换句话说,每块硬盘上的主用副本和备副本数量是均匀的。 扩容节点或者故障减容节点时,数据恢复重建算法保证了重建后系统中各节点负载的均衡性。 当Server3出现故障,丢失所有Disk3和Disk6上的数据块,但是数据不会丢失。 FusionStorage 缓存机制 写Cache流程
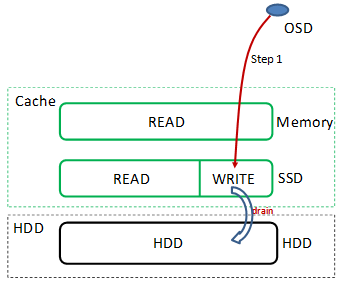
OSD在受到VBS发送的写IO操作时,会将写IO缓存在SSD Cache后完成本节点写操作。 OSD会周期将缓存在SSD Cache中的写IO数据批量写入到硬盘,写Cache有一个水位值,未到刷盘周期超过设定水位值也会将Cache中数据写入到硬盘中。 FusionStorage支持大块直通,按缺省配置大于256KB的块直接落盘不写Cache,这个配置可以修改 FusionStorage支持将服务器部分内存用作读缓存,NVDIMM和SSD用作写缓存。 读Cache流程
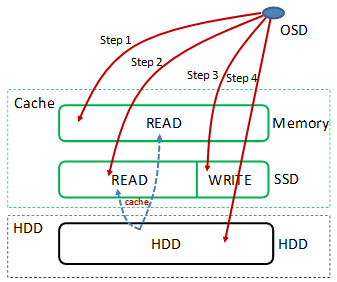
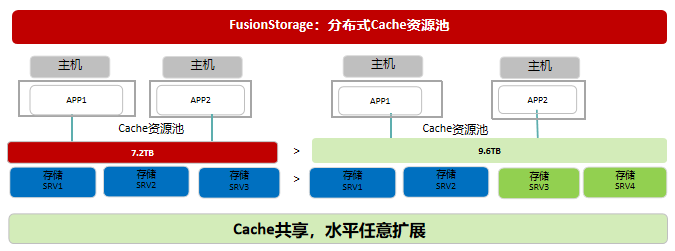
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。 OSD收到VBS发送的读IO操作的步骤处理: Step 1:从内存“读cache”中查找是否存在所需IO数据,存在则直接返回,并调整该IO数据到“读cache”LRU队首,否则执行Step 2 Step 2:从SSD的“读cache”中查找是否存在所需IO数据,存在则直接返回,并增加该IO数据的热点访问因子,否则执行Step 3 Step 3:从SSD的“写cache”中查找是否存在所需IO数据,存在则直接返回,并增加该IO数据的热点访问因子;如果热点访问因子达到阈值,则会被缓存在SSD的“读cache”中。如果不存在,执行Step 4 Step 4:从硬盘中查找到所需IO数据并返回,同时增加该IO数据的热点访问因子,如果热点访问因子达到阈值,则会被缓存在SSD的“读cache”中 读修复:在读数据失败时,系统会判断错误类型,如果是磁盘扇区读取错误,系统会自动从其他节点保存的副本读取数据,然后重新写入该副本数据到硬盘扇区错误的节点,从而保证数据副本总数不减少和副本间的数据一致性。 FusionStorage 分布式Cache
保电介质:NVDIMM内存、PCIe SSD卡、SSD硬盘 FusionStorage IO流程分析 读IO流程
APP下发读IO请求到OS,OS转发该IO请求到本服务器的VBS模块;VBS根据读IO信息中的LUN和LBA信息,通过数据路由机制确定数据所在的Primary OSD;如果此时Primary OSD故障,VBS会选择secondary OSD读取所需数据 Primary OSD接收到读IO请求后,按照Cache机制中的“Read cache机制”获取到读IO所需数据,并返回读IO成功给VBS 写IO流程
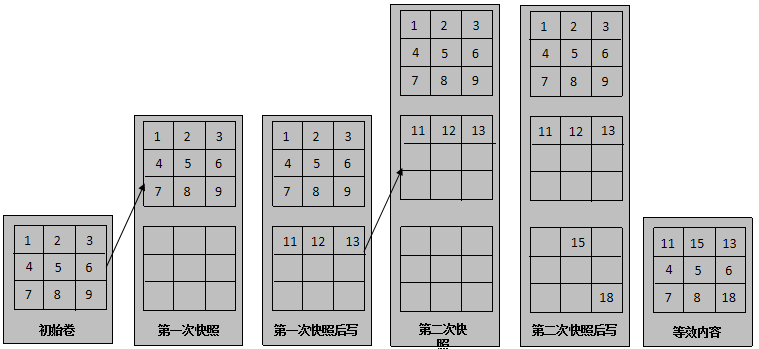
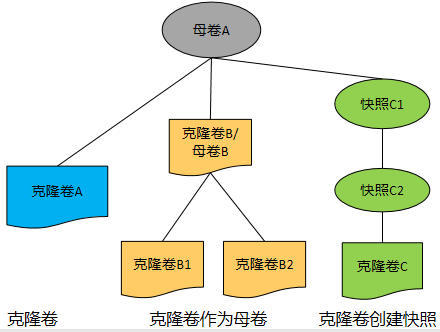
当主机能够支持安装VBS时,可以通过SCSI和iSCSI方式访问; 当主机不能够支持安装VBS时,只能通过iSCSI访问。 SCSI与iSCSI区别: 应用场景:看主机OS是否能安装VBS(FSA是一个Linux的rpm包),主机OS能支持安装VBS的,一般使用SCSI,比如:KVM、CNA等;主机OS闭源不支持安装VBS的,只能使用iSCSI,比如:ESXi、Windows等。 资源损耗:iSCSI有封装和解封装的过程,需要消耗主机的资源;SCSI直接走特殊总线。 传输介质:SCSI通过总线传输,iSCSI通过网络传输。 快照功能
迁移过程中,源卷不能有写操作,故叫冷迁移 整体流程: 创建目标卷 卷数据复制 删除源卷 目标卷改名 完成迁移应用场景: 资源池之间的容量平衡,例如高负载池迁移至低负载 卷在不同性能的资源池之间迁移,例如低性能向高性能池迁移 FusionStorage 部署方式 融合部署
管理平面:实现FSM与FSA之间的通信。 业务平面:实现VM或者主机与VBS之间的通信。 存储平面:实现MDC/VBS/OSD之间的交互。 |

【本文地址】
今日新闻 |
推荐新闻 |